
Overview
S.E.N.S.E. is a speculative framework I created to explore how AI can help people better understand the reliability of the information they consume, without restricting access, censoring content, or controlling what they see.
Grounded in the semantic and multimodal reasoning capabilities of Google Gemini, this project examines how extending existing Assistant and on-device intelligence could support users in evaluating information across text, images, videos, and audio. Instead of positioning AI as an authority that decides what is true, the intent is to use it as a quiet, supportive layer that helps people make sense of information when they choose to.
At its core, S.E.N.S.E. is about preserving freedom while reducing harm. People should be able to consume whatever content they want, but they should also have the ability to pause, seek context, and understand what they’re about to believe or share. By building on familiar Google interactions, the framework turns misinformation evaluation from a complex or intimidating task into a simple, user-invoked action, helping people consume and share information more responsibly, without taking control away from them.
Problem
Why Misinformation Feels Different Today
Misinformation has always existed, but the way it spreads today feels fundamentally different. Information now moves through fast, scroll-driven spaces like feeds, messages, and short videos, where speed matters more than scrutiny.
In these moments, people often react to a headline, an image, or a brief clip before context or credibility has time to catch up. The rise of AI has only intensified this shift. Realistic images, videos, and audio can make false claims feel authentic at a glance, turning misinformation into a multimodal problem rather than just a textual one.
What hasn’t evolved at the same pace is verification. Checking whether something is real still requires effort, intent, and a break in flow, while most information is consumed casually and on the move. This gap is what makes misinformation feel harder to manage today: not because people don’t care about accuracy, but because they lack simple, in-the-moment ways to pause and judge what they’re seeing.
Who Is Affected
Misinformation doesn’t affect everyone in the same way. The risks and consequences vary based on a person’s digital confidence, time constraints, and responsibility toward others.
I used the personas shown here to ground the project in real contexts. They helped me account for differences in pressure, confidence, and tolerance for friction when dealing with information, without assuming expertise or ideal behaviour.
Rather than designing for a single type of user, these perspectives reinforced the need for a system that remains flexible, optional, and respectful of individual context.



How People Consume & Share Information
Through conversations with people across different age groups, I looked for patterns in how information is consumed and shared in everyday digital spaces. Rather than focusing on platforms or demographics, the goal was to understand behavioural tendencies that make misinformation easy to absorb and spread.
Key patterns that consistently emerged:
People skim more than they read
Most users rely on headlines, thumbnails, captions, or short clips instead of opening full articles. Despite limited context, they still form opinions and participate in discussions.
Sharing often happens without verification
Content is forwarded because it feels interesting, alarming, or socially relevant. Sharing is often used as a way to “discuss” rather than to endorse accuracy.
Fact-checking is largely passive
When verification does happen, it’s usually indirect, through comments, reactions, or cues from others—rather than deliberate source checking.
Trust is driven by familiarity, not credibility
Information from friends, family, influencers, or familiar pages is more readily believed, even when the original source is unclear.
Emotional content lowers the threshold for sharing
Fear, outrage, humour, and feel-good narratives increase engagement and impulsive sharing, often bypassing critical evaluation.
Visual content is assumed to be authentic
Images and videos significantly increase perceived credibility, despite widespread awareness that visuals are easy to manipulate.
Algorithmic influence is underestimated
Many users believe they are in control of what they see, without realizing how engagement-driven algorithms amplify sensational or misleading content.
Taken together, these behaviours suggest that misinformation spreads less because of intent, and more because current systems do not support thoughtful evaluation at the moment of consumption or sharing.
Key Insights That Shaped the Direction
Synthesising the research revealed that misinformation isn’t primarily a problem of awareness, as most people already know fake news exists. The challenge lies in how information fits into everyday behaviour, and where existing systems fall short.
A few insights directly shaped the direction of this project:
Verification must fit into the moment of consumption
People rarely leave their current context to fact-check. Any meaningful intervention needs to work where information is encountered, not somewhere else.
Binary labels don’t reflect how information evolves
Many claims exist in a grey area like emerging science, developing events, or incomplete reporting. Treating everything as “true” or “false” creates false certainty and erodes trust.
Uncertainty needs to be acknowledged, not hidden
Especially for scientific knowledge and breaking news, ambiguity is often the most honest state. Showing uncertainty is more useful than forcing conclusions.
Control matters more than automation
Users are more receptive to tools they can invoke themselves. Systems that intervene unprompted risk feeling intrusive or paternalistic, even when well-intentioned.
Visual credibility is misleadingly high
Images and videos significantly increase perceived trust, even though they are easier than ever to manipulate. Any solution must work beyond text alone.
People want clarity, not confrontation
Correcting misinformation publicly can feel socially risky. Tools that offer private, non-judgmental context are more likely to be used consistently.
Together, these insights pointed toward a solution that is optional, context-aware, multimodal, and honest about uncertainty. One that supports better decisions without trying to control behaviour.
Why the Current Process Falls Short
Google already offers a way to quickly look up information. A long-press gesture can surface Google Search or related results, which in theory should help people verify what they’re seeing.
To understand how this works in practice, I asked the same group of people about this interaction and how often they use it. What emerged wasn’t resistance, but misalignment with real behaviour.
A noticeable portion of people weren’t aware that such a feature existed at all, particularly among those over 45.
Several people had seen it appear on their phones but weren’t clear on what it was meant for or how it could help them verify information.
Many had tried it once or twice, usually to identify an object or place in an image, but not to assess the credibility of content or news.
Only a small handful actively understand the feature but don’t often use it, as it takes them away from the natural flow of scrolling or sharing.
When asked why they don’t rely on this process to verify information, a few themes consistently surfaced:
Limited awareness or unclear purpose
Many didn’t associate the interaction with evaluating misinformation or credibility.
A disruptive context switch
The process leads to a separate Google Search experience, requiring people to leave the content, scan results, and interpret multiple sources.
Effort outweighs intent
For moments where the goal is simply to share something or respond in a conversation, this level of effort feels disproportionate.
Almost all participants made it clear that they didn’t want to dig deep into details or explanations. What they cared about was something much simpler: knowing whether what they were seeing was real or fake, especially before forwarding something.
This gap between powerful search capabilities and lightweight, in-context clarity highlighted the need for a different approach that fits naturally into how people already consume and share information, rather than asking them to step away from it.
Design Intent & Principles
Once the problem and behavioural patterns became clear, the direction of the solution followed naturally. The intent wasn’t to stop misinformation at the source or police what people see, but to support better judgment at the moment it matters most.
These principles guided every decision in the framework, from interaction design to how outcomes are communicated.
Preserve freedom of consumption
People should be able to consume any content they want. The system should never block, hide, or restrict information. Instead of controlling access, the goal is to support awareness, allowing users to decide for themselves what to believe or share.
Be user-invoked, not system-imposed
Any intervention around misinformation carries the risk of feeling intrusive or paternalistic. To avoid this, the system is activated only when the user asks for it, keeping control firmly in their hands and building trust over time.
Fit into existing behaviour, not disrupt it
People scroll, skim, and act quickly. Asking them to pause, navigate multiple screens, or absorb additional explanations creates friction. The experience needed to feel lightweight, immediate, and in-context.
Avoid false certainty
Not all information is clearly right or wrong. Scientific knowledge evolves, events unfold in real time, and evidence is often incomplete. The system should acknowledge uncertainty honestly, rather than forcing binary conclusions.
Work across formats, not just text
Modern misinformation isn’t limited to articles or headlines. Images, videos, voice notes, and short clips shape belief. Any meaningful solution needs to evaluate claims across formats, not treat visuals as inherently trustworthy.
Reduce harm without assigning blame
Most misinformation spreads unintentionally. The tone, language, and feedback of the system should be private and non-judgmental, helping users feel informed rather than corrected or embarrassed.
Together, these principles shaped a direction that prioritizes clarity over control, support over enforcement, and trust over authority, laying the foundation for a framework that could realistically fit into how people already interact with information.
Why Gemini
Once the intent and constraints were clear, the question wasn’t whether AI should be involved, but what kind of AI could realistically support this without overstepping.
I anchored this framework to Google Gemini because the problem of misinformation is not about retrieving information. It is about understanding claims in context. Gemini’s strengths align closely with that need.
Understanding meaning, not just keywords
Verifying information is not as simple as matching words to search results. The same claim can appear in different forms, tones, or formats. Gemini’s semantic reasoning allows it to focus on what a piece of content is actually claiming, rather than reacting to surface-level patterns or keywords.
This is critical for avoiding false positives and for handling nuanced or incomplete information honestly.
Designed for multimodal information
Misinformation today rarely exists as text alone. Claims are embedded in images, short videos, voice notes, screenshots, and combinations of all three.
Gemini’s multimodal capabilities make it suitable for evaluating content across formats and treating different media as expressions of the same underlying claim.
Comfortable with uncertainty
Many claims, especially around science or developing events, do not have clear final answers. Gemini’s probabilistic reasoning makes it possible to surface uncertainty instead of forcing certainty.
This aligns closely with the framework’s goal of avoiding binary judgments while still being useful.
Works naturally at the OS and Assistant level
Because Gemini already underpins Assistant and on-device intelligence, it offers a realistic path to in-context evaluation.
Reasoning can happen closer to the content itself, at the moment users encounter it, without forcing them into a separate search or verification flow.
Enables support, not surveillance
Gemini can be used on demand rather than monitoring content continuously. This allows the system to respect privacy and avoid constant intervention.
Users remain in control of when evaluation happens and what they choose to act on.
In this project, Gemini is not positioned as a judge of truth. It serves as the reasoning layer that makes semantic understanding, multimodal evaluation, and honest uncertainty possible, creating the conditions for a framework like S.E.N.S.E. to exist responsibly.
Introducing the S.E.N.S.E. Framework
With the problem, behaviours, and constraints clearly defined, the challenge became one of structure: how to evaluate information in a way that reflects how people actually consume it, quickly, casually, and across formats, without forcing certainty where it doesn’t exist.
I arrived at S.E.N.S.E. as a way to break this complexity down into something understandable and usable in the moment. Rather than treating misinformation as a single, uniform problem, the framework approaches it through layered reasoning that focuses on meaning, context, and evidence before arriving at any outcome.
S.E.N.S.E.
Semantic Evaluation for Nuanced Source Examination
Designed to answer a simple question people already have when they encounter content: “Can I trust this?”, without requiring them to search, interpret multiple sources, or step out of their flow.
The framework is built around three key ideas.
Understand the claim before judging it
Instead of reacting to keywords or formats, S.E.N.S.E. focuses on identifying the underlying claim being made, regardless of whether it appears as text, an image, a video, or audio.
Different claims require different logic
Scientific statements and real-world events behave differently and evolve at different speeds. Treating them the same leads to misleading outcomes. S.E.N.S.E. separates these domains so each can be evaluated appropriately.
Outcomes should reflect evidence, not absolutes
Not everything is clearly right or wrong. By acknowledging uncertainty and evidence gaps, the framework avoids false confidence while still offering meaningful guidance.
Together, these ideas form a lightweight reasoning model that can operate quietly in the background and surface clarity only when a user asks for it. S.E.N.S.E. does not attempt to control what people see or believe. It exists to support better judgment at the moment of consumption or sharing, using AI as an assistant rather than an authority.
How S.E.N.S.E. Evaluates Claims
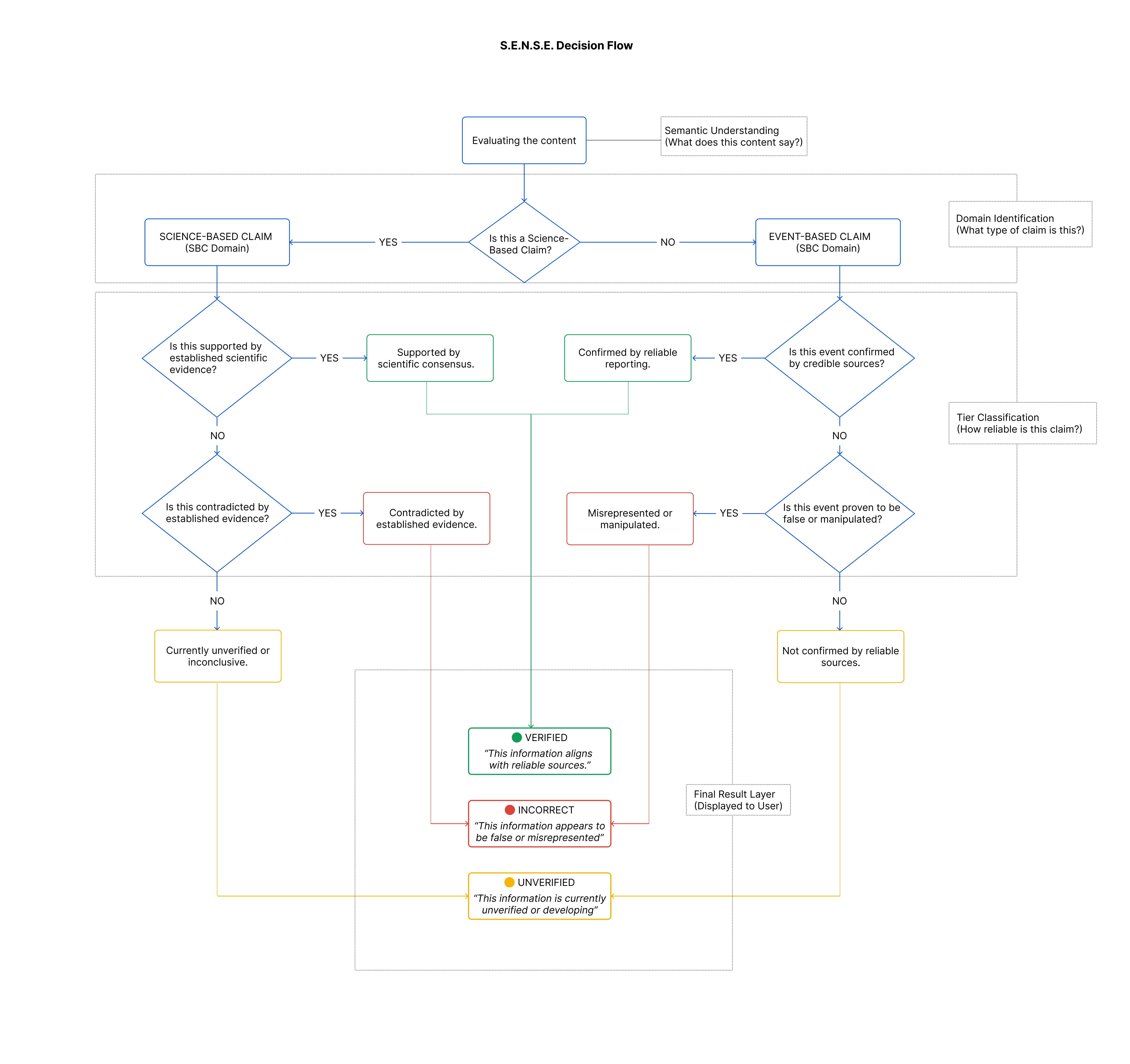
Domains: Understanding What Kind of Claim This Is
While people consume a wide variety of content online, misinformation tends to appear most often in a specific subset of it: content that makes claims about reality and can influence beliefs or decisions.
Through research, I found that these higher-risk claims can be understood through two broad domains. This is not a classification of all online content, but a practical lens to help people assess claims that are more likely to be misleading or misrepresented.
Science-Based Claims
These include statements related to scientific facts, health, medicine, environment, technology, or research findings. Such claims often evolve over time as evidence accumulates and consensus forms.
- Health advice
- Climate or environmental claims
- Scientific explanations or discoveries
Because scientific knowledge is rarely static, this domain requires greater tolerance for uncertainty.
Event-Based Claims
These relate to real-world events, actions, or statements tied to specific moments in time.
- News about policies, laws, or elections
- Claims about incidents or public statements
- Viral stories involving people or organisations
Event-based claims often converge toward verification faster, but are also more prone to distortion, exaggeration, or fabrication.
Separating these domains ensures that a developing scientific idea is not treated the same way as a fabricated event, and vice versa.
Tiers: Reflecting Evidence, Not Certainty
Once a claim’s domain is identified, S.E.N.S.E. evaluates it across three evidence-based tiers. These tiers are intentionally simple and familiar, mirroring how people intuitively think about information.
Tier 1: Verified
The claim aligns with credible sources or established evidence within its domain. This does not imply absolute truth, but indicates that the information is broadly consistent with what is currently known or verified.
Tier 2: Incorrect
The claim conflicts with reliable evidence or verified information. This tier is used when available sources clearly indicate that the claim is inaccurate or misleading.
Tier 3: Unverified
The claim cannot be confidently confirmed or denied with current evidence. This includes emerging scientific ideas, developing events, or incomplete and conflicting information.
This tier exists to acknowledge uncertainty, not to label content as wrong.
By separating what kind of claim something is from how strong the evidence is, S.E.N.S.E. avoids forcing binary judgments onto complex information. This domain-and-tier approach forms the backbone of the framework, making it adaptable, transparent, and better aligned with how information actually exists and evolves in the real world.
This decision flow aims to keep evaluation:
By breaking complex reasoning into clear, sequential steps, S.E.N.S.E. makes it possible to bring AI-supported clarity into everyday information consumption, without turning verification into a burden.
Interaction Model: User Activation Loop
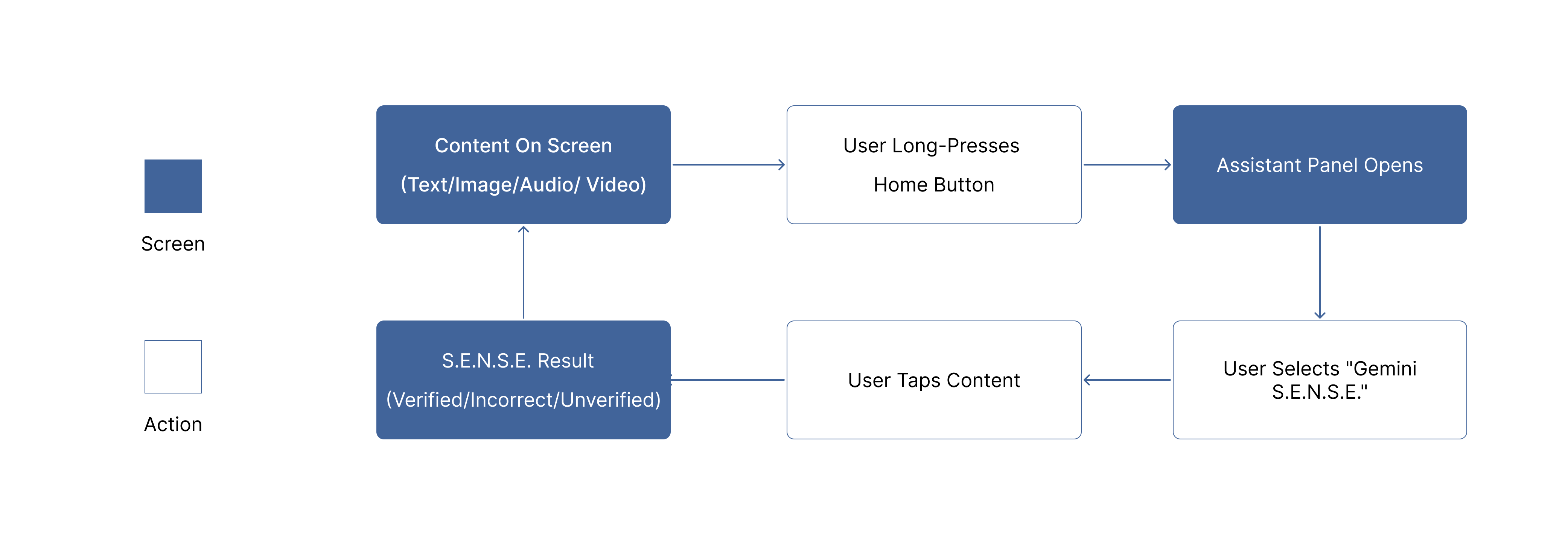
The interaction model for S.E.N.S.E. is built around a simple idea: clarity should be available, but never forced. Since misinformation often spreads during quick, casual moments like scrolling, skimming, or sharing, the experience needs to fit naturally into those moments without interrupting them.
Rather than introducing a new app or workflow, S.E.N.S.E. is designed as a user-invoked loop that sits alongside existing behaviour.
Encountering Content (No Intervention)
Users consume information the same way they always do through social media feeds, messaging apps, videos, images, or websites. At this stage, S.E.N.S.E. remains completely invisible.
There are no prompts, warnings, or overlays by default. This ensures that normal consumption isn’t disrupted and avoids creating alert fatigue or unnecessary anxiety.
Intentional Invocation
When a user feels unsure, or simply curious, they can activate S.E.N.S.E. from the Assistant panel that appears when they long-press the home button.
This moment is important. It signals intent. The system responds only because the user actively chooses the S.E.N.S.E. option, not because it decided to intervene on its own.
Content-First Evaluation
Once activated, the user taps the specific piece of content (text, image, video, or audio) they want to understand better.
S.E.N.S.E. evaluates the content itself, not the platform it appears on. This keeps the experience focused and avoids assumptions based on source or format.
Clear, Lightweight Feedback
The outcome is surfaced quickly and in simple language, giving the user a sense of whether the content appears Verified, Incorrect, or Unverified, based on available evidence.
The feedback supports a quick decision, especially before sharing. An option to explore more context is available, but entirely optional. Users can just as easily dismiss the result and continue scrolling.
Return to Content (The Loop Closes)
After seeing the result, the user returns seamlessly to the original content. They can continue scrolling, choose not to share, or decide to look deeper elsewhere.
The system doesn’t linger, follow up, or enforce behaviour. Each interaction is self-contained, reinforcing trust and preventing dependency.
Why I designed it as a loop
This circular interaction of content → intent → clarity → content ensures that S.E.N.S.E. fits into everyday behaviour rather than competing with it. By keeping activation optional and outcomes lightweight, the model respects attention, autonomy, and context.
The result is a system that supports better judgment without changing how people naturally use their devices, making verification feel like a natural extension of consumption rather than an additional task.
What the User Sees: S.E.N.S.E. Output States
The goal of S.E.N.S.E. isn’t to explain everything or overwhelm users with sources. The output is intentionally lightweight, designed to answer the question users care about most in the moment: Can I trust this, or should I pause before sharing?
Each state reflects the strength of available evidence, using neutral language that’s easy to understand at a glance.
Verified
This state indicates that the information is broadly consistent with what is currently known. It doesn’t imply absolute truth, only a high level of confidence based on available evidence.
Incorrect
This appears when credible evidence clearly contradicts the claim. The focus stays on the mismatch between the claim and evidence, without assigning intent or blame.
Unverified
This includes developing events, emerging scientific ideas, or incomplete information. The system explicitly acknowledges uncertainty instead of forcing a conclusion.
Visual & Interaction Cues
The colour system follows a familiar traffic-light logic to support quick understanding:
- Green (Verified): Safe to proceed
- Yellow (Unverified): Pause and be cautious
- Red (Incorrect): Stop and reconsider
Icons and typography remain minimal and neutral. There are no alerts, sounds, or interruptions. The feedback appears quietly and disappears just as easily.
Interaction Decisions
- Optional depth: Users can explore more context if they want, but it’s never required.
- No forced actions: The system doesn’t block sharing or prompt confirmations.
- Instant return to flow: Users return seamlessly to the original content.
Why I Designed It This Way
Misinformation often spreads in moments of speed and uncertainty. By pairing simple language with familiar visual cues, S.E.N.S.E. supports better decisions without pressure or disruption.
The system doesn’t tell users what to do. It gives them a clear signal and leaves the choice in their hands.
Mock-up: User Activation Loop
To visualise how S.E.N.S.E. fits into everyday behaviour, I created a simple mock-up of the user activation loop. In this scenario, a user encounters content, invokes S.E.N.S.E., checks credibility, and returns seamlessly to scrolling.
For the mock-up, I used a placeholder icon for S.E.N.S.E. based on concentric circles in Google’s primary colours. The form is inspired by a telescope viewed from above, symbolising the idea of looking far and beyond for clarity. The icon is placed with the rest of the options without drawing unnecessary attention or interrupting the flow.




The S.E.N.S.E. icon appears alongside existing Assistant options without drawing unnecessary attention. There are no prompts, alerts, or interruptions by default, reinforcing that clarity is available, but never forced.
Edge Cases & Failure Modes
Any system designed to evaluate information must be honest about its limits. Misinformation is rarely clean, static, or intentional, and there are situations where even a well-designed framework like S.E.N.S.E. can produce incomplete or ambiguous outcomes.
Rather than treating these as exceptions to hide, I considered them explicitly during the design process to ensure the system fails transparently and responsibly.
Ambiguous or Vaguely Worded Claims
Some content is intentionally unclear or loosely phrased, making it difficult to identify a concrete claim. In such cases, S.E.N.S.E. avoids forcing interpretation and defaults to signalling uncertainty.
Rapidly Developing Events
Breaking news and unfolding situations often lack stable or consistent evidence. Early information may change quickly, making confident judgments unreliable.
Satire, Parody, or Humour
Satirical content can resemble misinformation when shared outside its original context. Rather than relying on tone detection alone, the system prioritises caution when intent is unclear.
Niche or Low-Visibility Topics
Some claims relate to highly specialised, local, or under-documented topics where authoritative sources are limited or unavailable.
Subtly Manipulated Media
Cropped images, partial videos, or removed context can mislead without being fully fabricated. These cases are difficult to detect with certainty.
Over-Reliance on the System
There is a risk that users may begin to treat S.E.N.S.E. as an authority rather than a support tool. Language and interaction design deliberately avoid absolute conclusions to counter this.
Designing for these failure modes reinforced a central principle of the framework: it is better to be transparently uncertain than confidently wrong. S.E.N.S.E. is designed to support judgment, not replace it.
Ethical & Responsible Design Considerations
In a problem space as sensitive as misinformation, restraint is as important as capability. While exploring S.E.N.S.E., I was mindful that even well-intentioned tools can unintentionally shape behaviour, suppress voices, or create misplaced trust if not designed carefully.
The following constraints were intentional. They define what S.E.N.S.E. does not attempt to do, in order to preserve user agency, avoid overreach, and remain aligned with real-world behaviour.
It does not censor, block, or restrict access to content
S.E.N.S.E. never restricts access to information. Content remains fully visible and accessible, regardless of its evaluation outcome. The system supports awareness, not control.
It does not overlook uncertainity
Information, especially around science and developing events, is rarely absolute. Presenting AI outputs as definitive risks misleading users and eroding trust over time. The inclusion of an Unverified state is a deliberate ethical choice. It allows the system to admit uncertainty rather than forcing false confidence, reinforcing the idea that not knowing is sometimes the most accurate response.
It does not decide what is true or false for the user
Outcomes are presented as evidence-based signals, not final judgments. The system avoids absolute language and leaves interpretation and action entirely in the user’s hands.
It does not intervene without explicit user intent
S.E.N.S.E. remains inactive by default. There are no automatic warnings, overlays, or prompts. Evaluation only occurs when the user actively invokes the system.
It does not monitor or analyse content continuously
The framework is designed for on-demand use rather than passive surveillance. This avoids privacy concerns and reinforces that evaluation is a choice, not a background process.
It does not force deeper explanations or actions
Users are never required to read additional context, explore sources, or justify their decisions. Depth is available, but always optional.
It does not replace human judgment
S.E.N.S.E. is designed as a support layer, not an authority. It exists to assist reasoning at the moment of consumption, not to substitute critical thinking or personal responsibility.
I defined these boundaries explicitly so that S.E.N.S.E. avoids becoming a system that polices information or dictates belief. Instead, it remains focused on its core purpose: offering clarity when users ask for it, and stepping back when they do not.
Product Strategy & Feasibility
Although S.E.N.S.E. is a speculative framework, I was deliberate about grounding it in how such a system could realistically exist. The focus was on fitting into existing ecosystems, reducing friction, and scaling responsibly without overreach.
1. Building on existing user behaviour
S.E.N.S.E. extends interactions people already understand, such as invoking the Assistant through a long-press gesture, rather than introducing a new app or workflow.
From a product standpoint, this lowers adoption barriers. Users do not need to learn new behaviours or change how they consume content. The framework fits into moments that already exist, making use more likely without requiring habit formation.
2. OS-level integration over platform dependency
Instead of relying on individual platforms to adopt verification features, S.E.N.S.E. is conceived as an OS-level capability.
- Consistent behaviour across apps and content formats
- Reduced dependence on platform-specific policies
- Broader coverage, including private messaging contexts
- A single, coherent mental model for users
By operating closer to the system layer, the framework remains neutral and widely applicable.
3. On-demand evaluation to manage cost and risk
Continuous background evaluation would be expensive, intrusive, and ethically questionable. S.E.N.S.E. avoids this by being entirely user-invoked.
Evaluation happens only when a user explicitly requests it, which reduces computational load, limits unnecessary data processing, aligns with privacy expectations, and avoids alert fatigue.
4. A deliberately narrow scope
The framework is intentionally focused. It helps users understand whether content appears Verified, Incorrect, or Unverified at the moment they encounter it.
It does not attempt to explain topics in depth, debate opinions, infer intent, or enforce actions. Keeping the scope tight makes the system easier to trust, easier to reason about, and easier to scale without unintended consequences.
5. Measuring success beyond engagement
Traditional engagement metrics are a poor fit for a system designed to reduce impulsive behaviour. Instead, success signals focus on decision quality.
- Frequency of voluntary use over time
- Reduced sharing after Incorrect or Unverified outcomes
- User-reported confidence in understanding content
- Repeat invocation in ambiguous situations
6. Incremental rollout and learning
From a product strategy perspective, S.E.N.S.E. could evolve gradually. Starting with text and images, expanding to video and audio, refining domain logic through real-world usage, and improving clarity through language and micro-interactions.
This incremental approach reduces risk while allowing the system to adapt to actual behaviour and feedback.
Overall, the feasibility of S.E.N.S.E. rests on a simple premise: it does not ask users or platforms to do more than they already do. By aligning with existing interactions, respecting constraints, and keeping scope intentionally focused, the framework positions itself as a realistic extension of on-device intelligence rather than an idealised solution.
Future Evolution
I approached S.E.N.S.E. as a foundation rather than a finished system. Its long-term value lies in how it can evolve thoughtfully in response to real behaviour, emerging risks, and new information formats, without compromising its core principles. Any evolution would need to remain user-invoked, transparent, and respectful of agency.
1. Scam detection in messages and emails
A future evolution of S.E.N.S.E. could help users assess whether a message or email appears suspicious or misleading, using the same semantic and contextual reasoning applied elsewhere.
This would be particularly valuable for users vulnerable to impersonation scams, phishing attempts, or fabricated alerts. As with the rest of the framework, this capability would remain user-invoked, private, and non-blocking.
2. Deeper multimodal understanding
As misinformation increasingly appears in video and audio formats, future iterations could strengthen how manipulated visuals, edited clips, or synthetic media are evaluated.
This would allow S.E.N.S.E. to reason not just about explicit claims, but also about implied narratives created through framing or visual context.
3. Contextual learning over time
With user consent, the system could learn from repeated interactions to better handle ambiguity and edge cases.
This learning would focus on improving pattern recognition and judgment quality, not personal profiling, keeping privacy intact.
4. Adaptation to local and cultural context
Information ecosystems vary widely across regions. Future versions could better account for local context, language nuance, and regional sources to reduce misinterpretation and bias.
This would be essential for maintaining trust at scale.
5. Continuous ethical review
As the system evolves, ethical considerations would need ongoing review, particularly around bias, misuse, and over-reliance.
Any future changes should be guided by the same restraint that shaped the original framework: supporting judgment without exerting control.
Rather than aiming to eliminate misinformation entirely, I see the future of S.E.N.S.E. as a quiet, adaptive layer of support. One that grows in capability over time while remaining grounded in human judgment, choice, and trust.
Final Reflection
S.E.N.S.E. began with a simple but unsettling observation. Misinformation often spreads due to a mismatch between how information is consumed today quickly, emotionally, and across formats and how verification tools are designed. When checking accuracy requires effort, context switching, or expertise, it is usually the first thing people skip.
This project does not try to eliminate misinformation. Instead, it asks a more practical question: what if people had a simple way to pause and decide for themselves, right where the content appears?
By grounding the framework in Google Gemini’s semantic and multimodal reasoning, I explored how AI can act as a supportive layer rather than an authority. Throughout the process, I was deliberate about restraint. The system is user-invoked, private, and lightweight. The goal was never to replace critical thinking, but to make it easier to practice in everyday moments.
Ultimately, this case study reflects how I approach product and UX problems. I start with real behaviour, design for complexity without overengineering, and build systems that support confidence without taking control away from people.